数据中心架构
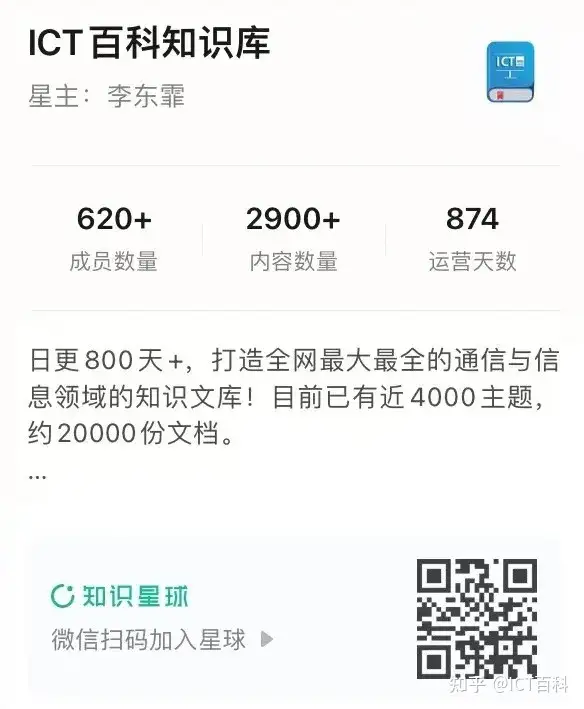
目前数据中心流行的是 CLOS 网络架构:Spine+Leaf 网络架构,如下图所示:
Spine-Leaf架构
CLOS 网络通过等价多路径实现无阻塞性和弹性,交换机之间采用三级网络使其具有可扩展、简单、标准和易于理解等优点。
除了支持 Overlay 层面技术之外,Spine+Leaf 网络架构的另一个好处就是,它提供了更为可靠的组网连接,因为 Spine层面与 Leaf 层面是全交叉连接,任一层中的单交换机故障都不会影响整个网络结构。
流量模型
但由于CLOS网络架构中的many-to-one流量模型和all-to-all 流量模型,数据中心中无法避免的常常出现 Incast 现象,这是造成数据中心网络丢包的主要原因。
1. many to one 流量模型
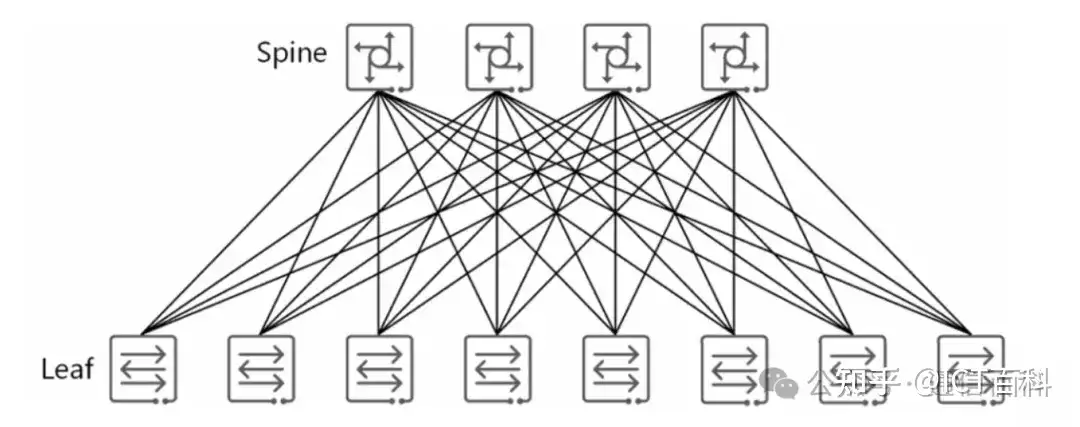
如下图所示是many to one流量模型。leaf1、leaf2、leaf3、leaf4 和spine1、spine2、spine3形成一个无阻塞的 CLOS 网络。假设服务器上部署了某分布式存储业务,某个时间内,server2 上的应用需要从 server1、server3、server4 处同时读取文件,会并发访问这几个服务器的不同数据部分。
many to one流量模型
每次读取数据时,流量从 server1 到 server2、从server3 到 server2、从 server4 到 server2,形成一个 many-to-one,这里是 3 打1。整网无阻塞,只有leaf2向server2的方向出端口方向产生了一个3打1的Incast现象,此处的buffer是瓶颈。无论该buffer有多大,只要many-to-one持续下去,最终都会溢出,即出现丢包。
一旦丢包,会进一步恶化影响业务性能指标(吞吐和时延)。增加 buffer 可以缓解问题,但不能彻底解决问题,特别是随着网络规模的增加、链路带宽的增长,增加buffer 来缓解问题的效果越来越有限。
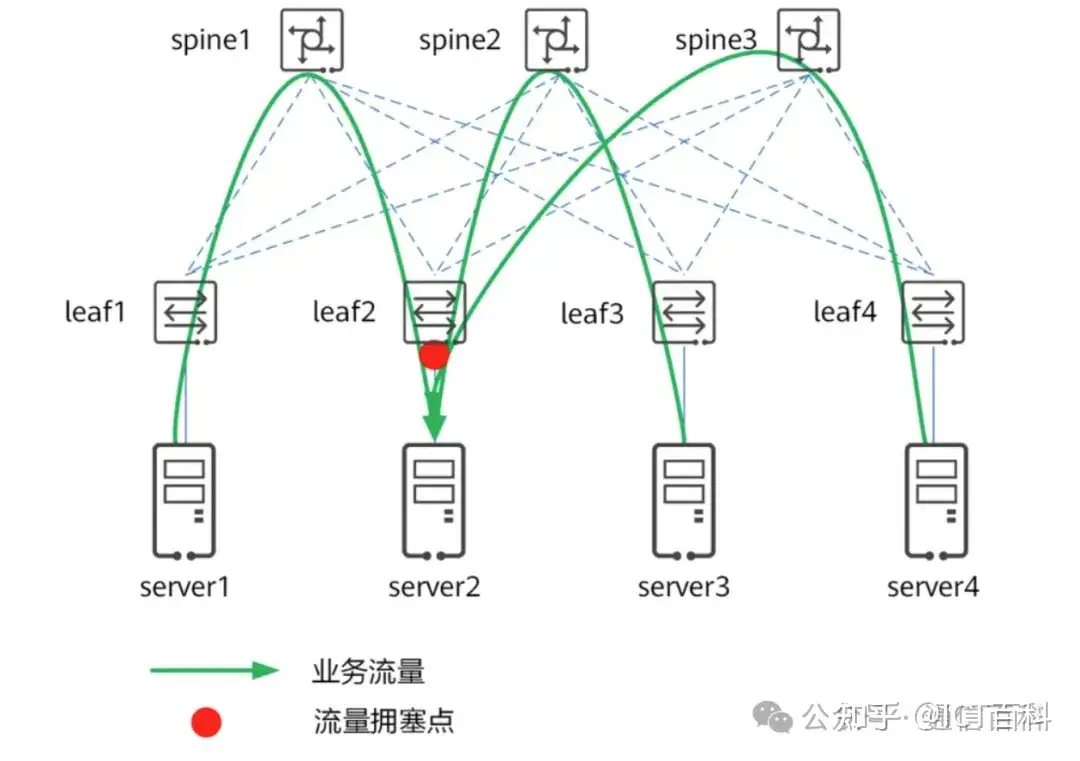
同时,大容量芯片增加 buffer 的成本越来越高,越来越不经济。要在 many-to-one 流量模型下实现无损网络,达成无丢包损失、无时延损失、无吞吐损失,唯一的途径就是引入拥塞控制机制,目的是控制从 many 到 one 的流量、确保不超过one侧的容量,如图所示。
many to one流量控制
为了保证不出现 buffer 溢出而丢包,交换机 leaf2 必须提前向源端发送信号抑制流量,同时交换机必须保留足够的 buffer 以在源端抑制流量之前接纳报文,这些操作由拥塞控制机制完成。当然,这个信号也可以由服务器 server2 分别发给server1、server3和server4。
因为信号有反馈时延,为了确保不丢包,交换机是必须有足够的 buffer 以在源端抑制流量之前容纳排队的流量,buffer 机制没有可扩展性,这意味着除了拥塞控制机制之外,还需要链路级流量控制。
2. all to all 流量模型
如下图所示是all to all流量模型。leaf1、leaf2、leaf3 和 spine1、spine2、spine3 形成一个无阻塞的 CLOS 网络。假设服务器上部署了某分布式存储业务,server1 与 server4 是计算服务器,server2 与server3 是存储服务器。
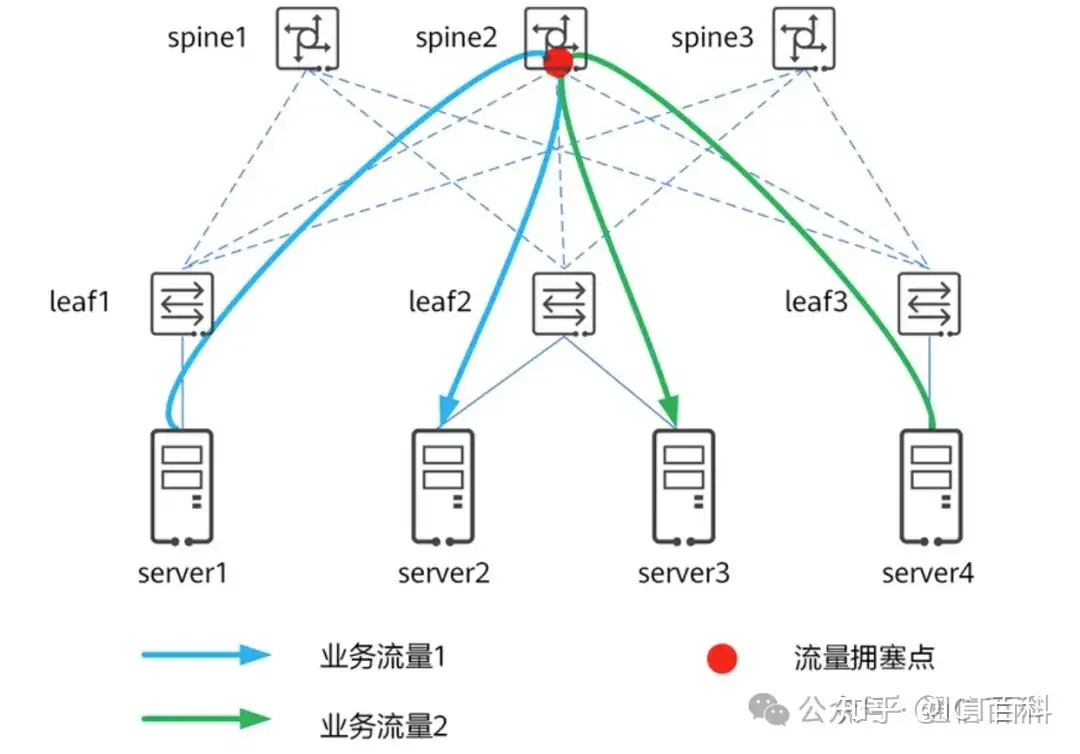
all to all流量模型
当server1向server2写入数据、server4向server3 写入数据时,流量从 server1 到 server2、从 server4 到 server3,两个不相关的one-to-one 形成一个all-to-all,这里是 2打2。整网无阻塞,只有spine2向leaf2 的方向出端口方向是一个2打1的Incast流量,此处的buffer是瓶颈。无论该buffer 有多大,只要 all-to-all 持续下去,最终都会溢出,即出现丢包。一旦丢包,会进一步恶化影响吞吐和时延。要在 all-to-all 流量模型下实现无损网络,达成无丢包损失、无时延损失、无吞吐损失,需要引入负载分担,目的是控制多个 one 到 one 的流量不要在交换机上形成交叉,如下图所示,流量从 server1 到 spine1 到 server2、从 server4 到spine3 到server3,整网无阻塞。
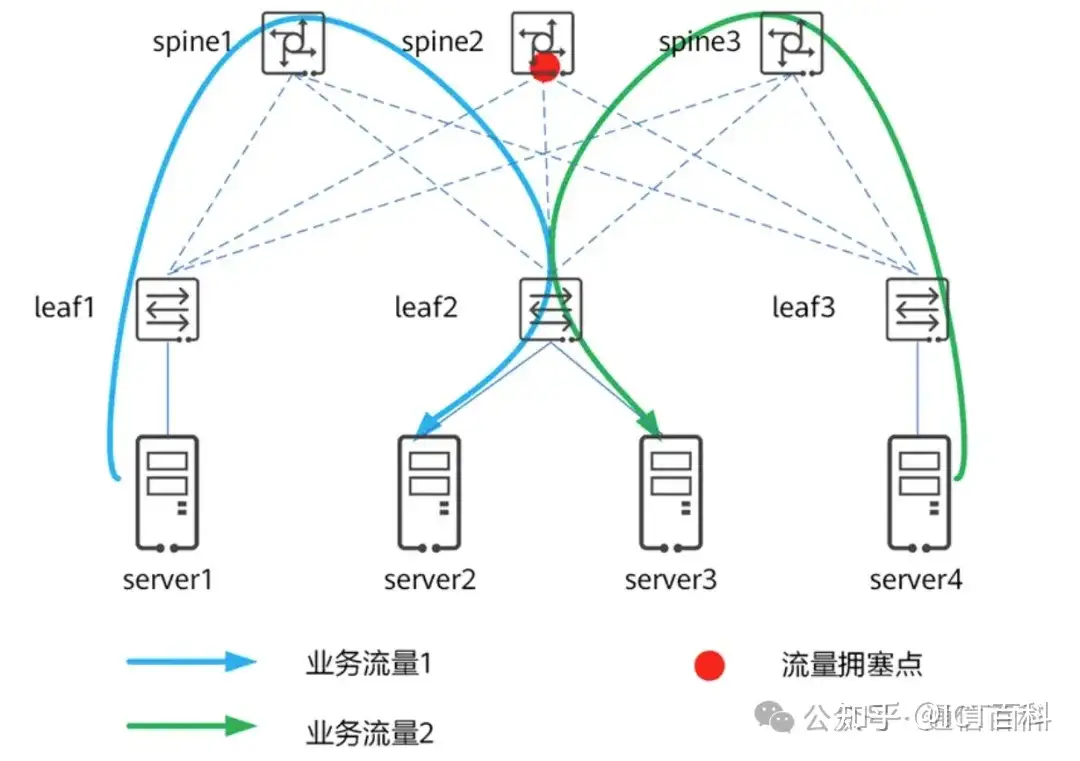
all to all 下流量负载分担
事实上,报文转发、统计复用就意味着有队列、有 buffer,不会存在完美的负载分担而不损失经济性。如果采用大 buffer 吸收拥塞队列,则成本非常高且在大规模或大容量下无法实现,比如这里单纯使用大buffer 保证不丢包,spine2的 buffer 必须是所有下接leaf的buffer总和。
为了整网不丢包,除了 buffer 以外,还得有流量控制机制以确保点到点间不丢包。如图下 所示,all-to-all 流量模型下,采用的是“小 buffer 交换机芯片+流量控制”,由小buffer的spine2 向leaf1 和leaf3发送流量控制信号,让leaf1和leaf3抑制流量的发送速率,缓解spine2的拥塞。
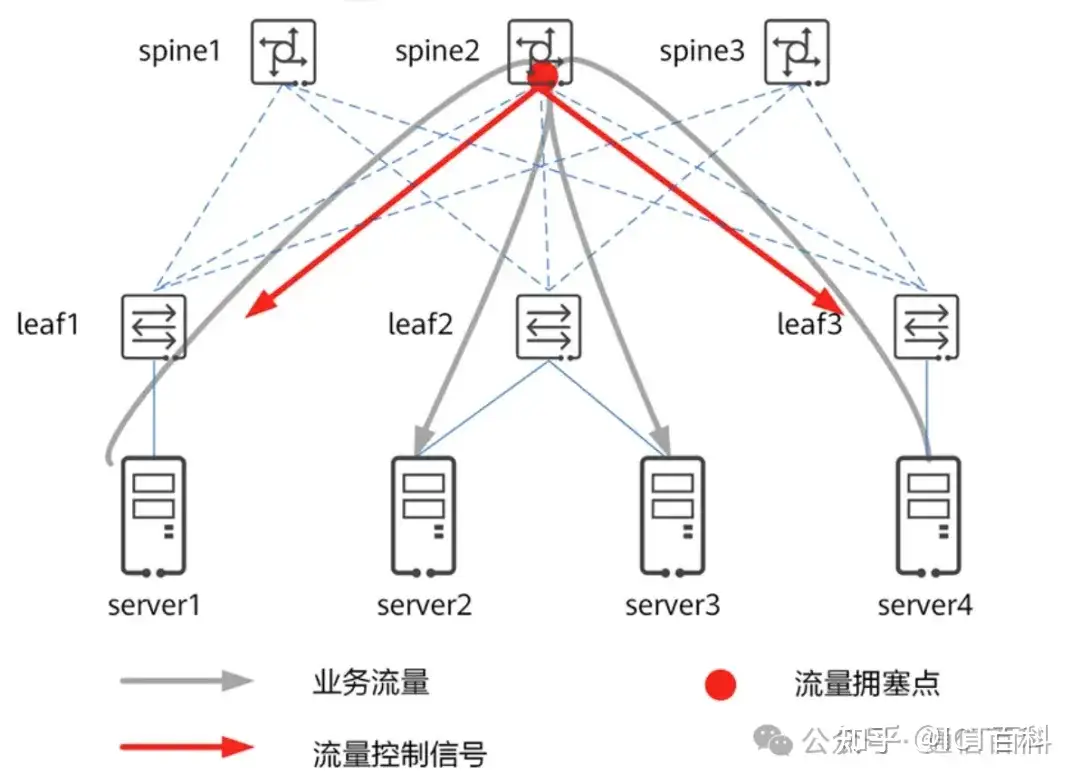
all to all 下链路级流控
拥塞控制是一个全局性的过程,目的是让网络能承受现有的网络负荷。网络拥塞从根源上可以分为两类,一类是对网络或接收端处理能力过度订阅导致的 Incast 型拥塞,可产生在如 many-to-one 流量模型的数据中心网络,其根因在于多个发送端往同一个接收端同时发送报文产生了多打 1 的 Incast 流量;另一类是由于流量调度不均引起的拥塞,比如 all-to-all 流量模型的数据中心网络,其根因在于流量进行路径选择时没有考虑整网的负载分担使多条路径在同一个交换机处形成交叉。
ECN拥塞控制
解决 Incast 现象引起的拥塞,往往需要交换机、流量发送端、流量接收端协同作用,并结合网络中的拥塞反馈机制来调节整网流量才能起到缓解拥塞、解除拥塞的效果。
ECN(Explicit Congestion Notification)ECN 是一种优雅的方式来处理网络拥塞,因为它允许网络设备在实际丢包发生之前进行调整。这种方法可以减少因丢包导致的延迟和重传,从而提高网络的吞吐量和效率。有如下优势:
- 所有流量发送端能够早期感知中间路径拥塞,并主动放缓发送速率,预防拥塞发生。
- 在中间交换机上转发的队列上,对于超过平均队列长度的报文进行 ECN 标记,并继续进行转发,不再丢弃报文。避免了报文的丢弃和报文重传。
- 由于减少了丢包,发送端不需要经过几秒或几十秒的重传定时器进行报文重传,提高了时延敏感应用的用户感受。
- 与没有部署ECN 功能的网络相比,网络的利用率更好,不再在过载和轻载之间来回震荡。
因此,中间交换机通过对将ECN字段置为11,就可以通知流量接收端本交换机是否发生了拥塞。当流量接收端收到ECN字段为11的报文时,就知道网络上出现了拥塞。这时,它向流量发送端发送协议通告报文,告知流量发送端存在拥塞。流量发送端收到该协议通告报文后,就会降低报文的发送速率,避免网络中拥塞的加剧。
当网络中拥塞解除时,流量接收端不会收到ECN字段为11的报文,也就不会往流量发送端发送用于告知其网络中存在拥塞的协议通告报文。此时,流量发送端收不到协议通告报文,则认为网络中没有拥塞,从而会恢复报文的发送速率。
以上为 ECN 简单的原理,那么 ECN 门限和 PFC 门限是什么关系呢?下面以图为例:
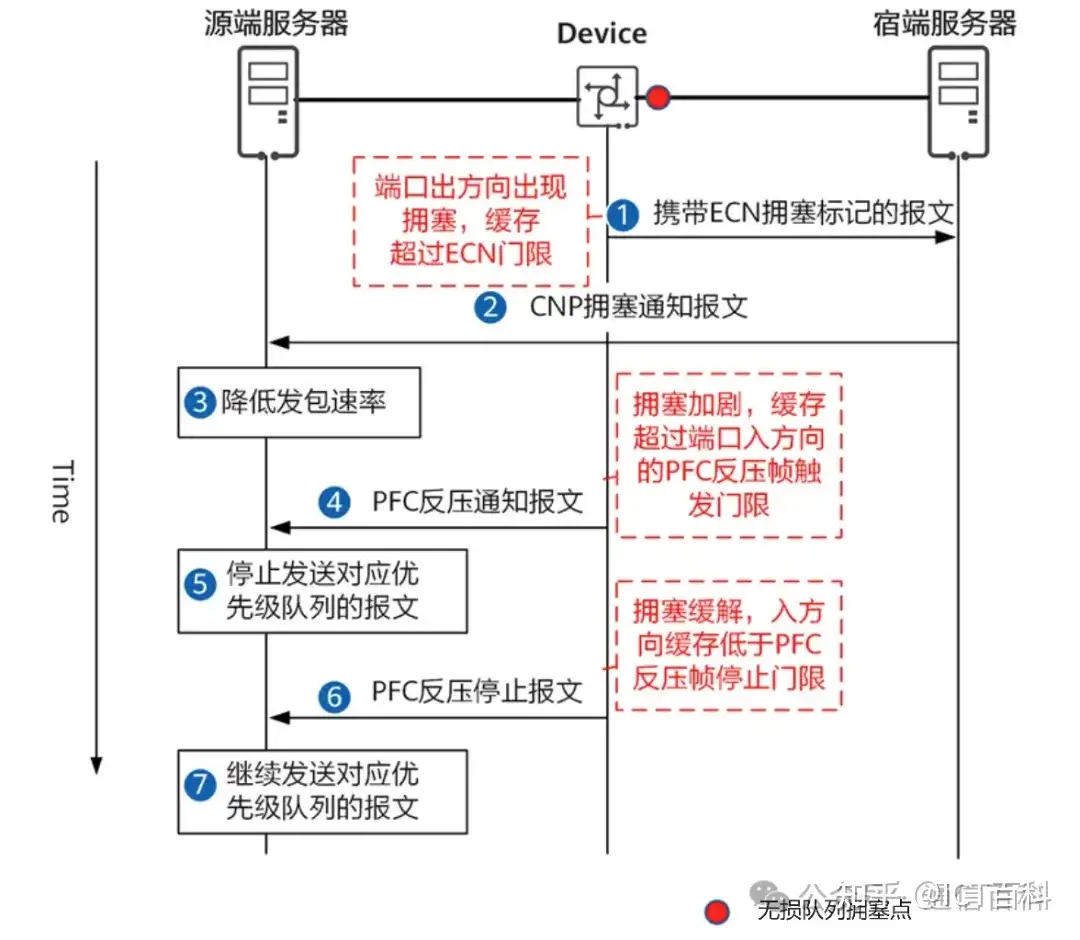
- 当Device 设备的无损队列出现拥塞,队列已使用的缓存超过 ECN 门限时,Device 设备在转发报文中打上ECN拥塞标记(将ECN字段置为11)。
- 宿端服务器收到携带ECN拥塞标记的报文后,向源端服务器发送CNP拥塞通知报文。源端服务器收到CNP拥塞通知报文后,降低发包速率。
- 当Device 设备的无损队列拥塞加剧,队列已使用的缓存超过PFC反压帧触发门限时,Device 设备向源端服务器发送 PFC 反压通知报文。源端服务器收到 PFC反压通知报文后,停止发送对应优先级队列的报文。
- 当Device 设备的无损队列拥塞缓解,队列已使用的缓存低于PFC反压帧停止门限时,Device 设备向源端服务器发送 PFC 反压停止报文。源端服务器收到 PFC反压停止报文后,继续发送对应优先级队列的报文。
由上面的过程可以看出,从Device设备发现队列缓存出现拥塞触发ECN标记,到源端服务器感知到网络中存在拥塞降低发包速率,是需要一段时间的。
在这段时间内,源端服务器仍然会按照原来的发包速率向Device发送流量,从而导致Device设备队列缓存拥塞持续恶化,最终触发 PFC 流控而暂停流量的发送。
因此,需要合理设置ECN门限,使得ECN 门限和 PFC门限之间的缓存空间能够容纳ECN 拥塞标记之后到源端降速之前这段时间发送过来的流量,尽可能的避免触发网络PFC流控。
欢迎加入我们的社群,有大量数据中心相关的资料文档,目前已持续更新800+天!